Emerging Technology: OCR and the benefits to a business using new cloud technologies
In this post we will discuss the benefits of OCR to a business, although OCR has been around for a long time there have been some huge progressive steps involving cloud-based providers and machine learning capabilities to accurately identify your data, therefore reducing time-consuming data entry business processes.
There are several popular cloud-based and standalone OCR engines each with varying pricing options and also varying accuracy from open source to large license-based costs. With cloud-based OCR solutions, there has been dramatic progress to allow small companies to national or international organizations to take advantage of the latest technologies on a “pay as you go” contract without large initial licensing costs.
There are several cloud options currently on the market, to name a few Abbyy Cloud, Google Cloud Vision, Microsoft Azure Computer Vision, and more recently Amazon Textract.
To understand where a business could benefit from these cloud options firstly, we need to understand the basics of OCR technology.
DOCUMENT FORMAT
Typically, a business document could be in:
- Structured Format – meaning there are clear areas in this document that are of business importance, in an invoice, for example, we would be interested in ‘Form’ areas showing the invoice details (addresses, invoice numbers, etc) and a ‘Table’ area showing repeated lines of information such as invoice lines for services or products provided.
- Unstructured Format – it would be less common for these to be uploaded to a database readable format as these documents may take the form of a letter or contract, but again they may be stored depending on your business processes.
ZONAL RECOGNITION
A historic problem with OCR in business has been ‘zonal recognition’ meaning for example if a customer scanned or photographed a document that you need to read, there would be no identifiable co-ordinates on a page for you to extract a specific piece of information.
Some products on the OCR market allow an operator to ‘train’ the application and define approximate areas of an incoming document the locations of key data, one of the main issues with this is you are restricted to only specific document types you have trained your system for and also document formats do change, this is technically intensive to maintain.
OCR ACCURACY
Another key issue historically has been the accuracy of the data you may extract from a document during the OCR process. With the advent of RPA technologies where you try to remove as much operator intervention as you can to streamline the speed and accuracy of your processes, you need to ensure you have a high level of “Confidence” in the values you are reading and pass documents/data to the exception for “Human Intervention” where you suspect the data may not be as accurate as you wish. It is important to caveat that with current technology no OCR process will ever be 100% accurate, but as a business you should be aiming to build a business process utilizing “Confidence” return values from a product, to automate as much as you can.
This post will not go into detail about the specific accuracy of individual products but there are lots of posts on the internet that discuss this in a low level of technical detail sampling different types of documents on different OCR products.
During a lot of the Mekkanos testing and experience from working with other clients, we have tested a lot of different OCR products and one of the stand-out products that met all the challenges previously seen in business OCR was a newcomer to the OCR market, Amazon Textract.
TEXTRACT
We will not explain the product in detail but at a high level, it is a machine learning OCR product that is trained on thousands of different types of legal and company forms to identify specific information in it.
A quick summary of the advantages we have noticed over other OCR solutions.
- Amazon Textract will identify ‘Structured’ data in a document and return a detailed API response with the characteristics of your document, what we have done at Mekkanos is develop secondary API calls (available for demonstration on request) that translates the Amazon complex responses into simple readable REST responses that could be used by any system with REST capability.
- Amazon Textract has no reliance on Zonal training, so this allows your organization to read and get meaningful data from any type of ‘structured’ document without human intervention, business rules would still need to be built into this to process the extracted data, but this would be the case in a ‘Zonal Trained’ document also.
- Pricing is based on the number of pages that are processed, which is very beneficial if you are not expecting huge amounts of documents and avoid paying large licensing and support costs.
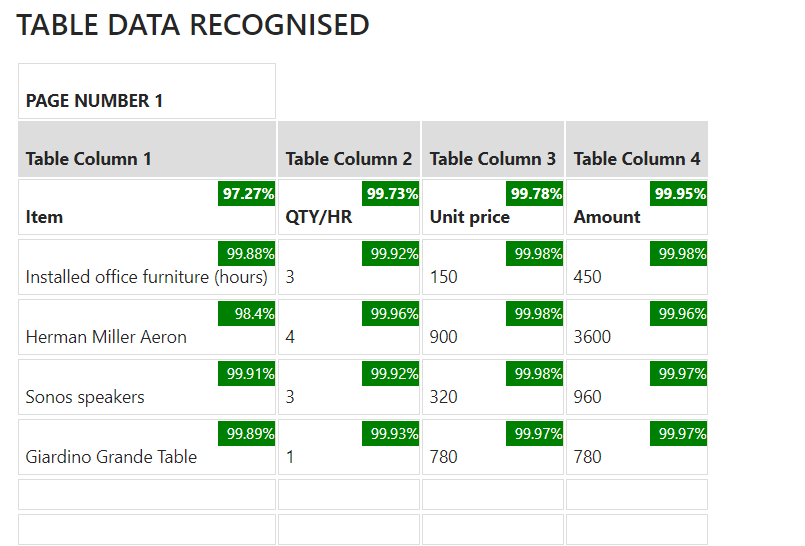
- The accuracy of reading data we have noticed is very high when compared to other OCR products cloud or standalone. Along with this, for every piece of extracted data a “Confidence” level on the read data is provided, this can be built into your own business processes to guess where manual intervention may be required and what you allow to be automatically processed.
IMAGE FROM A DEMO TEXTRACT ON A SAMPLE DOCUMENT
Author
Ray Paul Bsc